
Mastering the Power of Deep Learning Techniques: Unlocking the Potential of Artificial Intelligence
Deep learning is a form of artificial intelligence (AI) that uses algorithms to enable computers to learn from large amounts of data. It is a subset of machine learning, which is the study of algorithms that allow machines to learn from data. Deep learning techniques are used in a wide range of applications such as computer vision, natural language processing, speech recognition, and more.
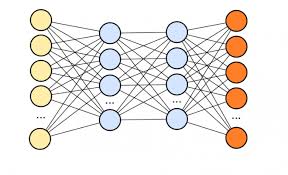
The main idea behind deep learning is to build networks of artificial neurons (also known as nodes) that are connected in different layers. Each neuron receives input from other neurons and processes it before passing it on to the next layer. This process continues until the output layer produces the desired result.
One of the most popular deep learning techniques is convolutional neural networks (CNNs). These networks are used for tasks such as image classification and object detection. They work by extracting features from images and then using them to make predictions about what objects are present in an image.
Another popular deep learning technique is recurrent neural networks (RNNs). These networks are used for tasks such as language modeling and text generation. They work by taking sequences of words or characters and predicting what comes next in the sequence.
Deep reinforcement learning is another powerful technique for AI applications such as robotics and game playing. It works by having an agent interact with its environment, receiving rewards when it performs certain actions correctly. The agent then learns from this experience over time, allowing it to make better decisions in the future.
Deep learning has revolutionized many areas of AI research and has enabled machines to perform tasks that were previously impossible for computers to do reliably. By leveraging large datasets and powerful computing resources, deep learning techniques can be used to solve complex problems that would otherwise be too difficult or time consuming for traditional methods.
Demystifying Deep Learning: 9 Frequently Asked Questions Answered
- What is deep learning?
- How does deep learning work?
- What are the advantages of deep learning?
- What are some common applications of deep learning?
- What tools and frameworks are used for deep learning?
- How can I get started with deep learning?
- What challenges do we face when using deep learning techniques?
- How can I evaluate the performance of a deep learning model?
- Is it possible to use pre-trained models in my own projects?
What is deep learning?
Deep learning is a subset of machine learning, which is a branch of artificial intelligence (AI). It involves training artificial neural networks to learn and make intelligent decisions by processing vast amounts of data. Deep learning algorithms are designed to mimic the way the human brain works, with interconnected layers of artificial neurons that process and analyze information.
The term “deep” in deep learning refers to the depth of these neural networks, which typically consist of multiple hidden layers. Each layer learns to extract increasingly complex features from the input data, allowing the network to understand intricate patterns and relationships.
Deep learning has gained significant attention and popularity due to its exceptional performance in various domains, including computer vision, natural language processing, speech recognition, and more. It has achieved remarkable breakthroughs in tasks such as image classification, object detection, machine translation, sentiment analysis, and voice assistants.
One key advantage of deep learning is its ability to automatically learn hierarchical representations from raw data without relying on handcrafted features. This means that deep learning models can learn directly from raw images, audio signals, or text without extensive manual feature engineering.
To train a deep learning model, large labeled datasets are required. These datasets serve as training examples for the neural network to adjust its internal parameters through a process called backpropagation. By iteratively adjusting these parameters using optimization techniques like stochastic gradient descent, the model gradually improves its performance on the given task.
Deep learning has revolutionized many industries by enabling machines to perform complex tasks with high accuracy levels. Its applications range from self-driving cars and medical diagnosis systems to recommendation systems and fraud detection algorithms. As research continues to advance in this field, deep learning holds immense potential for solving even more intricate problems and driving further advancements in artificial intelligence.
How does deep learning work?
Deep learning works by using artificial neural networks, which are inspired by the structure and function of the human brain. These networks consist of interconnected nodes, also known as artificial neurons, organized in layers.
The basic building block of a deep learning network is a neuron. Each neuron takes input values, applies mathematical operations to them, and produces an output. The output is then passed on to other neurons in the network.
Deep learning networks typically have multiple layers of interconnected neurons. The first layer is called the input layer and receives raw data as input, such as images or text. The last layer is called the output layer and produces the final result or prediction.
In between the input and output layers are hidden layers. These hidden layers perform complex computations on the input data to extract meaningful features and patterns. Each neuron in a hidden layer receives inputs from multiple neurons in the previous layer and passes its output to multiple neurons in the next layer.
During training, deep learning networks learn from large amounts of labeled data. They adjust their internal parameters, known as weights and biases, to minimize the difference between their predicted outputs and the correct outputs provided in the training data. This process is known as optimization or learning.
The adjustment of weights and biases is typically done using an algorithm called backpropagation. Backpropagation calculates how much each weight contributes to the overall error of the network’s predictions and updates them accordingly. This iterative process continues until the network’s performance reaches a satisfactory level.
One advantage of deep learning is its ability to automatically learn hierarchical representations from raw data without relying on explicit feature engineering. By iteratively processing data through multiple layers, deep learning networks can extract increasingly complex features that are useful for solving specific tasks.
Once trained, deep learning networks can make predictions or perform tasks on new, unseen data by passing it through their learned architecture. This ability to generalize from training data to unseen examples is one of the strengths of deep learning techniques.
Overall, deep learning is a powerful approach that has revolutionized many fields, allowing machines to learn from data and perform complex tasks that were previously challenging for traditional algorithms.
What are the advantages of deep learning?
High Accuracy: Deep learning algorithms have been shown to outperform many machine learning algorithms in terms of accuracy. This is due to their ability to learn complex patterns and features from data.
Automation: Deep learning algorithms are able to automate certain tasks, such as feature extraction, which may require manual effort when using traditional machine learning methods.
Scalability: Deep learning algorithms are highly scalable, meaning they can be easily adapted for different data sets and tasks.
Versatility: Deep learning algorithms can be used for a variety of tasks, including image classification, natural language processing, and time series analysis.
5. Low Maintenance: Once trained, deep learning models require minimal maintenance and can continue to learn from new data points as they become available.
What are some common applications of deep learning?
Deep learning has found applications in various fields, revolutionizing the way we approach and solve complex problems. Here are some common applications of deep learning:
- Computer Vision: Deep learning techniques, particularly convolutional neural networks (CNNs), have greatly advanced computer vision tasks such as image classification, object detection, facial recognition, and image segmentation. This has led to advancements in fields like autonomous vehicles, surveillance systems, medical imaging analysis, and augmented reality.
- Natural Language Processing (NLP): Deep learning models have made significant progress in understanding and generating human language. Applications include machine translation, sentiment analysis, chatbots, speech recognition systems (like virtual assistants), text summarization, and language generation.
- Recommender Systems: Deep learning algorithms are used to build personalized recommendation systems that suggest products or content based on user preferences and behavior. These systems are commonly seen in e-commerce platforms, music streaming services, video streaming platforms, and social media platforms.
- Healthcare: Deep learning techniques have been applied to medical imaging analysis for disease diagnosis and detection (such as cancer detection from mammograms or lung nodules from CT scans). They also play a role in genomics research for analyzing DNA sequences and predicting protein structures.
- Autonomous Vehicles: Deep learning plays a crucial role in enabling self-driving cars by processing real-time data from sensors like cameras and LiDAR to detect objects on the road, recognize traffic signs, interpret road conditions, and make driving decisions.
- Finance: Deep learning models are used for fraud detection by analyzing patterns in transaction data to identify suspicious activities. They are also applied in automated trading systems for forecasting stock prices or making investment decisions based on market trends.
- Gaming: Deep reinforcement learning has been employed to train agents that can play complex games at a superhuman level by interacting with the game environment and optimizing their strategies over time.
These are just a few examples of how deep learning is transforming various industries and enabling machines to perform tasks that were once considered challenging for computers. As technology continues to advance, the applications of deep learning are likely to expand further.
What tools and frameworks are used for deep learning?
The most popular tools and frameworks used for deep learning are TensorFlow, Keras, PyTorch, Caffe, Theano, MXNet, and Torch. These frameworks provide optimized libraries for deep learning algorithms such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), long short-term memory (LSTM) networks, and generative adversarial networks (GANs). Additionally, they provide tools for data preprocessing and visualization.
How can I get started with deep learning?
Learn the fundamentals of deep learning: Start by studying the basics of deep learning, such as neural networks, convolutional neural networks, and recurrent neural networks. You can find plenty of tutorials and resources online to help you get started.
Familiarize yourself with the different deep learning frameworks: There are several popular deep learning frameworks available, such as TensorFlow, Keras, PyTorch, and Caffe. Take some time to understand the differences between them and decide which one best suits your needs.
Experiment with datasets: Once you’ve chosen a framework, start experimenting with different datasets to get a feel for how deep learning works in practice. You can find plenty of open-source datasets online that you can use to explore the possibilities of deep learning.
4. Join an online community: Joining an online community is a great way to stay up-to-date with the latest developments in deep learning and connect with other practitioners who are also interested in this field.
What challenges do we face when using deep learning techniques?
While deep learning techniques have shown tremendous potential, they also come with several challenges that researchers and practitioners need to address. Some of the key challenges include:
- Data requirements: Deep learning models typically require a large amount of labeled data to train effectively. Acquiring and annotating such datasets can be time-consuming, expensive, or even infeasible in certain domains. Limited data can lead to overfitting or poor generalization.
- Computational resources: Deep learning models are computationally intensive and often require specialized hardware, such as powerful GPUs or TPUs, to train efficiently. This can be a barrier for individuals or organizations with limited access to such resources.
- Model interpretability: Deep learning models are often considered black boxes because they lack transparency in understanding their decision-making process. Interpreting and explaining the inner workings of these models is challenging, which may raise concerns regarding trust, accountability, and ethical implications.
- Training time: Training deep learning models can be time-consuming, especially for complex architectures and large datasets. Lengthy training times limit the ability to iterate quickly on model designs and experiment with different hyperparameters.
- Overfitting: Deep learning models are prone to overfitting when they memorize training data instead of generalizing patterns effectively. Regularization techniques like dropout and early stopping help mitigate this issue but require careful tuning.
- Lack of domain-specific knowledge: Deep learning techniques heavily rely on data-driven approaches rather than explicit domain knowledge incorporation. This can pose challenges when dealing with domains where limited labeled data is available or when expert knowledge is crucial for decision-making.
- Ethical considerations: As deep learning techniques become more prevalent in applications like facial recognition or autonomous vehicles, ethical concerns arise regarding privacy, bias, fairness, and potential misuse of these technologies.
Addressing these challenges requires ongoing research and development efforts focused on improving data availability, developing efficient algorithms for training on limited resources, enhancing interpretability, and ensuring ethical usage of deep learning techniques.
How can I evaluate the performance of a deep learning model?
Evaluating the performance of a deep learning model is crucial to understanding its effectiveness and making informed decisions. Here are some common methods for evaluating the performance of a deep learning model:
- Accuracy: Accuracy is a simple and widely used metric that measures the percentage of correctly predicted labels or classes. It is suitable for balanced datasets but may not be the best choice when dealing with imbalanced datasets.
- Precision, Recall, and F1-score: These metrics are commonly used in classification tasks, especially when dealing with imbalanced datasets. Precision represents the proportion of true positive predictions out of all positive predictions, while recall represents the proportion of true positives predicted correctly out of all actual positives. F1-score combines precision and recall into a single metric, providing a balanced evaluation.
- Confusion Matrix: A confusion matrix provides a detailed breakdown of correct and incorrect predictions across different classes or labels. It helps identify which classes are being misclassified more often and provides insights into model performance.
- ROC Curve and AUC: Receiver Operating Characteristic (ROC) curve plots the true positive rate against the false positive rate at various classification thresholds. The Area Under the Curve (AUC) summarizes the overall performance of a classifier, where an AUC value closer to 1 indicates better performance.
- Mean Squared Error (MSE): MSE is commonly used in regression tasks to measure how close predicted values are to actual values. It calculates the average squared difference between predicted and actual values.
- Cross-Validation: Cross-validation is useful for assessing model performance on different subsets of data to ensure generalizability. Techniques like k-fold cross-validation divide data into multiple subsets, training on one subset and evaluating on others iteratively.
- Speed and Resource Usage: In addition to accuracy metrics, it’s essential to evaluate how efficiently your deep learning model performs regarding speed and resource utilization such as memory usage or computational requirements.
Remember, the choice of evaluation metrics depends on the nature of your task, dataset, and specific requirements. It’s often beneficial to use a combination of metrics to have a comprehensive understanding of your deep learning model’s performance.
Is it possible to use pre-trained models in my own projects?
Yes, it is possible to use pre-trained models in your own projects. Pre-trained models are models that have already been trained on a specific dataset and can be used to make predictions or perform other tasks. They can be used as a starting point for creating a custom model for your project.
Deep learning is a form of artificial intelligence (AI) that uses algorithms to enable computers to learn from large amounts of data. It is a subset of machine learning, which is the study of algorithms that allow machines to learn from data. Deep learning techniques are used in a wide range of applications such as…